Helios v1
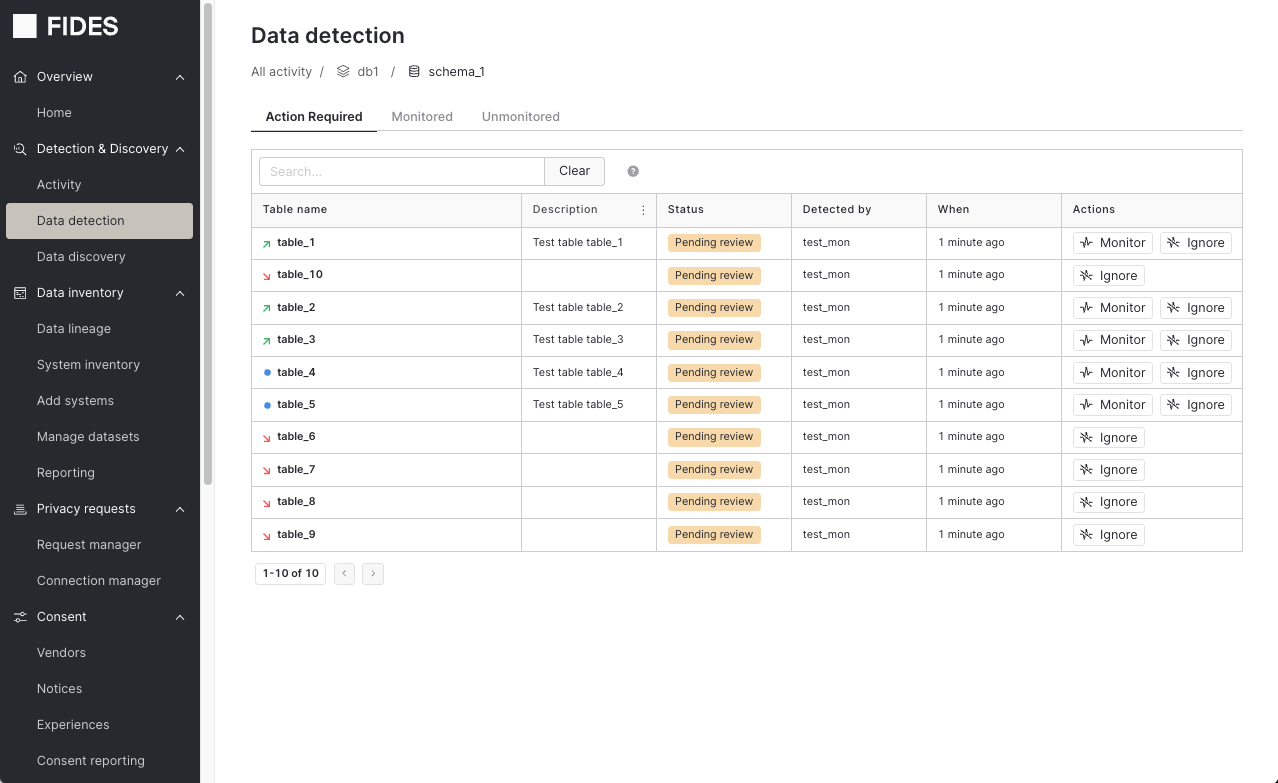
After completing a Scan, staged resources appear in the Data detection tab under Detection & Discovery. Within this page, choose which assets should be monitored for user data. If so, click Monitor; otherwise, click Ignore.
This decision can always be updated within the Monitored and Unmonitored tabs by selecting the available action (Ignore or Monitor).
Data Schema Updates
Monitors track changes in data schemas. Additions, such as a new column, appear with a green, upward arrow. Deletions, such as a dropped column, appear with a red, downward arrow. Other changes appear as a blue dot.
Data Discovery
After choosing to Monitor a schema, staged resources are promoted to the Data Discovery tab. This is where users review the data category tags assigned by the Fides classifier, making necessary adjustments to each field that was promoted. Click through the table rows to see how classifications are made during the automated discovery phase.
To update data category tags, click the data category assigned automatically. Then, search for the correct data category; the UI updates the Status to Reviewed after you update a data category.
When all the categories are reviewed and properly assigned, click Confirm all to commit the schema and classifications to a Fides dataset, which are viewable in the Manage datasets tab.
Classification
From the data schema and table view, use the Reclassify button to update the data category. This is useful only when you re-run classification:
- before discovery results have been committed to a dataset
- after updating a monitor configuration
Monitors can share configurations for regex annotation parameters. When a field matches a regex pattern, the corresponding data category is applied and the machine learning classification process is skipped for that field. This is especially useful when your data has similar naming schemas across assets.
For example, providing the regex mapping:
.*os_version -> user.device
classifies all field labels that contain os_version as user.device.